
段子网爬虫
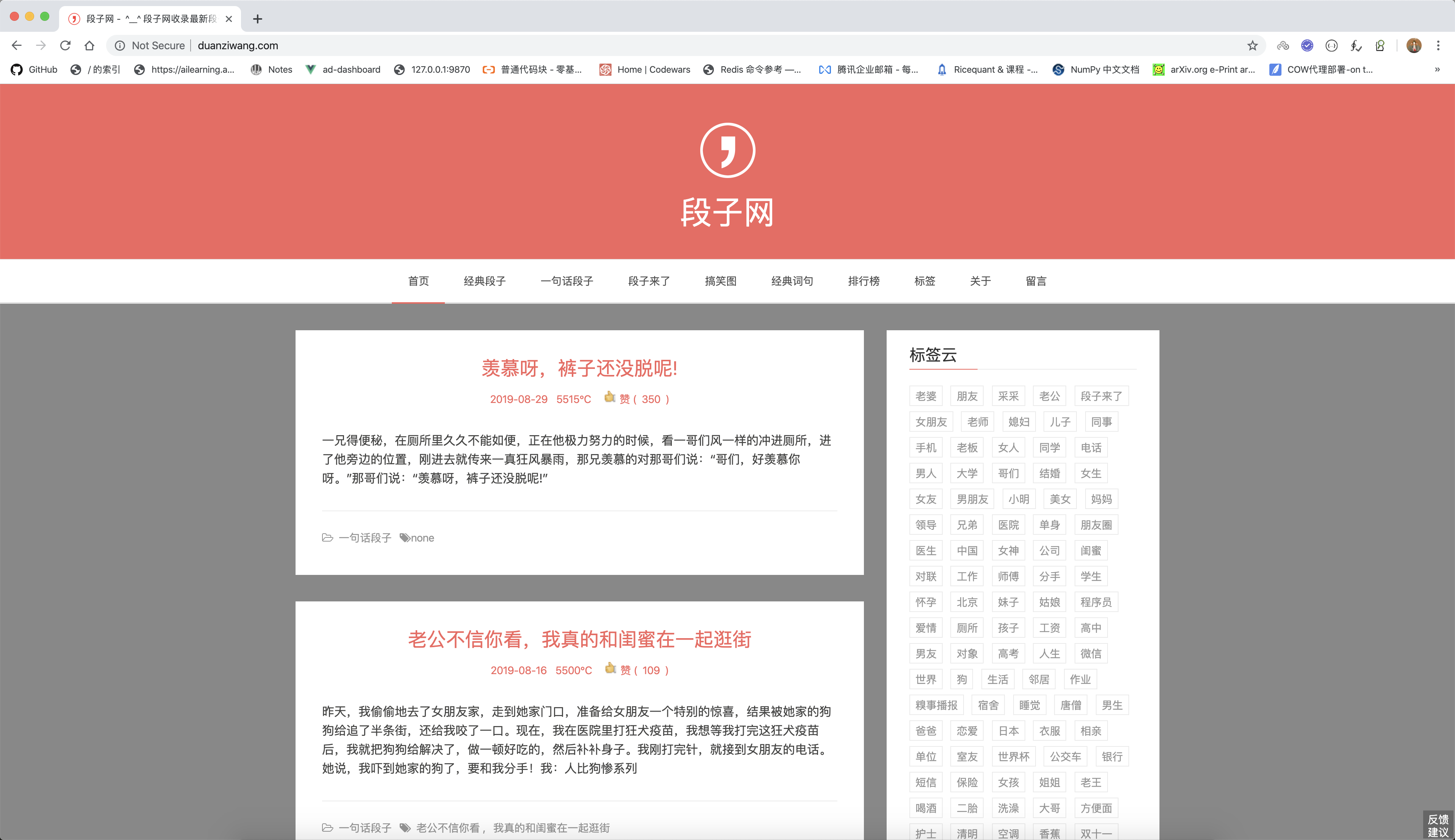
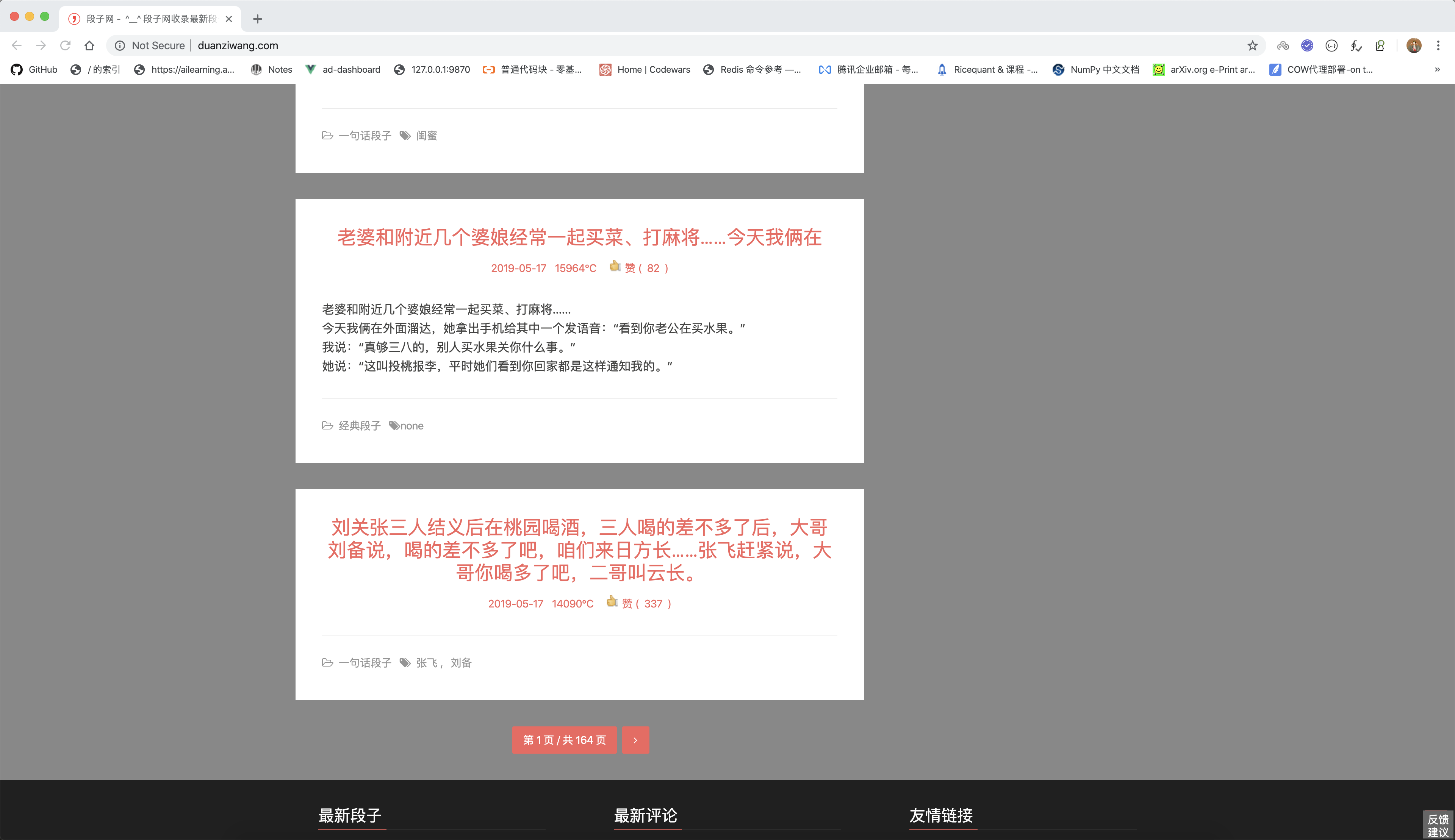
简单小爬虫, 不仅爬内容, 还爬样式。哈哈哈哈
import json
import hashlib
import time
import pymongo
import requests
import re
import threading
from pymongo import MongoClient
from qiniu import Auth, put_data
import multiprocessing
import sys
sys.path.insert(0, '/data/MyBlog')
from MyBlog.settings import MEDIA_URL
from MyBlog.utils import redis_client
from constants import MONGO_URI, MONGODB_NAME, QINIU_ACCESS_KEY, QINIU_SECRET_KEY, QINIU_BUCKET_NAME
class QiNiu(object):
def __init__(self):
self.user = Auth(QINIU_ACCESS_KEY, QINIU_SECRET_KEY)
self.bucket_name = QINIU_BUCKET_NAME
def up_stream(self, stream, key):
token = self.user.upload_token(self.bucket_name, key, 3600)
return put_data(token, key, stream, progress_handler=True)
def get_mongo():
return MongoClient(MONGO_URI, connect=False)[MONGODB_NAME]
mongodb = get_mongo()
qiniu_client = QiNiu()
class DuanziSpider(object):
def __init__(self, *arg, **kw):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.132 Safari/537.36'
}
self.base_url = 'http://duanziwang.com/'
self.mongodb = MongoClient(MONGO_URI)[MONGODB_NAME]
def req_and_write_base(self):
to_insert = []
old_ids = [int(i['id']) for i in list(self.mongodb['duanzi'].find())]
for i in range(1, 5000):
res = requests.get(url=self.base_url + 'page/{}/'.format(i), headers=self.headers)
if res.status_code not in (200, 201):
print('network error!')
continue
res.encoding = 'utf-8'
data = re.findall('<article id="(\d+)" class="post">([\S\s]*?)</article>', res.text)
# id, title, content, time, hot, like
for item in data:
if not item:
continue
_id = int(item[0])
if _id in old_ids:
continue
rest = item[1]
title = re.findall('<a href=".*">([\S\s]*?)</a>', rest)[0]
like = re.findall('<span>([\S\s]*?)</span>', rest)[0]
content = re.findall('<p>([\S\s]*?)</p>', rest)
if content:
content = content[0]
else:
content = ''
hot = re.findall('<time class="post-date">([\S\s]*?)</time>', rest)[0]
_time = re.findall('<time class="post-date" datetime=".*">([\S\s]*?)</time>', rest)[0]
to_insert.append({
'id': _id,
'title': title,
'content': content,
'time': _time,
'hot': hot,
'like': int(like),
})
print(to_insert)
if not to_insert:
print('no more new duanzi!')
return
self.mongodb['duanzi'].insert_many(to_insert)
def req_and_write_with_params(self, category):
old_ids = [int(i['id']) for i in list(self.mongodb['duanzi'].find())] + [1]
for i in range(1, 2000):
print(self.base_url + 'category/{}/{}/'.format(category, i))
try:
res = requests.get(url=self.base_url + 'category/{}/{}/'.format(category, i), headers=self.headers)
if res.status_code not in (200, 201):
print('network error!')
continue
except Exception as e:
print('{} {}'.format(e, self.base_url + 'category/{}/{}/'.format(category, i)))
continue
res.encoding = 'utf-8'
data = re.findall('<article id="(\d+)" class="post">([\S\s]*?)</article>', res.text)
# id, title, content, time, hot, like
for item in data:
if not item:
continue
_id = int(item[0])
if _id in old_ids:
continue
rest = item[1]
title = re.findall('<a href=".*">([\S\s]*?)</a>', rest)[0]
like = re.findall('<span>([\S\s]*?)</span>', rest)[0]
content = re.findall('<p>([\S\s]*?)</p>', rest)
if content:
content = content[0]
else:
content = ''
hot = re.findall('<time class="post-date">([\S\s]*?)</time>', rest)[0]
_time = re.findall('<time class="post-date" datetime=".*">([\S\s]*?)</time>', rest)[0]
temp = {
'id': _id,
'title': title,
'content': content,
'time': _time,
'hot': hot,
'like': int(like),
}
self.mongodb['duanzi'].insert(temp)
print(temp)
def main():
spider = DuanziSpider()
# spider.req_and_write_base()
categories = ['经典段子', '一句话段子', '段子来了', '搞笑图', '经典词句']
threads = list()
for c in categories:
t = threading.Thread(target=spider.req_and_write_with_params, args=(c,))
t.start()
threads.append(t)
for thread in threads:
thread.join()
links: https://www.mongona.com/?c=duanzi

相关推荐
开发者工具
Tags

请我喝咖啡
如果内容帮到了你,可以赞赏支持继续更新。
赏